引子
解决一些目前k3s在RiscV开发板上存在的问题。
kubectl&crictl
kubectl和crictl都是k3sCommandAPI中的命令,但是二者的运行结果却有所差异,我们可以从其差异中找到二者在使用上的异同。
不过需要提前强调的是,kubectl命令是从kubelet的角度看的逻辑状态,而crictl是从底层容器运行时的视角看的底层容器状态。
这是kubectl get pods的结果
kubectl get pods
NAME READY STATUS RESTARTS AGE
redis-696579c6c8-v2wns 1/1 Running 1 (7m57s ago) 30h
b6 0/1 ErrImagePull 0 (6d23h ago) 7d19h
这是crictl pods的结果
POD ID CREATED STATE NAME NAMESPACE ATTEMPT RUNTIME
cf657c901892e 5 minutes ago Ready helm-install-traefik-pv4hv kube-system 5 (default)
c60416658550d 5 minutes ago Ready local-path-provisioner-7b7dc8d6f5-48jjf kube-system 5 (default)
33c39dd34daff 5 minutes ago Ready helm-install-traefik-crd-ktfth kube-system 5 (default)
294e3dec339e2 5 minutes ago Ready metrics-server-668d979685-jthzj kube-system 5 (default)
8b67484f1bfe4 5 minutes ago Ready redis-696579c6c8-v2wns default 1 (default)
04ff59ad5464f 5 minutes ago Ready b6 default 5 (default)
2e1c2f055fb3e 5 minutes ago Ready coredns-b96499967-cpbrk kube-system 5 (default)
e0a0516a940da 30 hours ago NotReady redis-696579c6c8-v2wns default 0 (default)
ec8be446fcabf 7 days ago NotReady b6 default 0 (default)
首先从结果字段中来看,这些字段的含义如下:
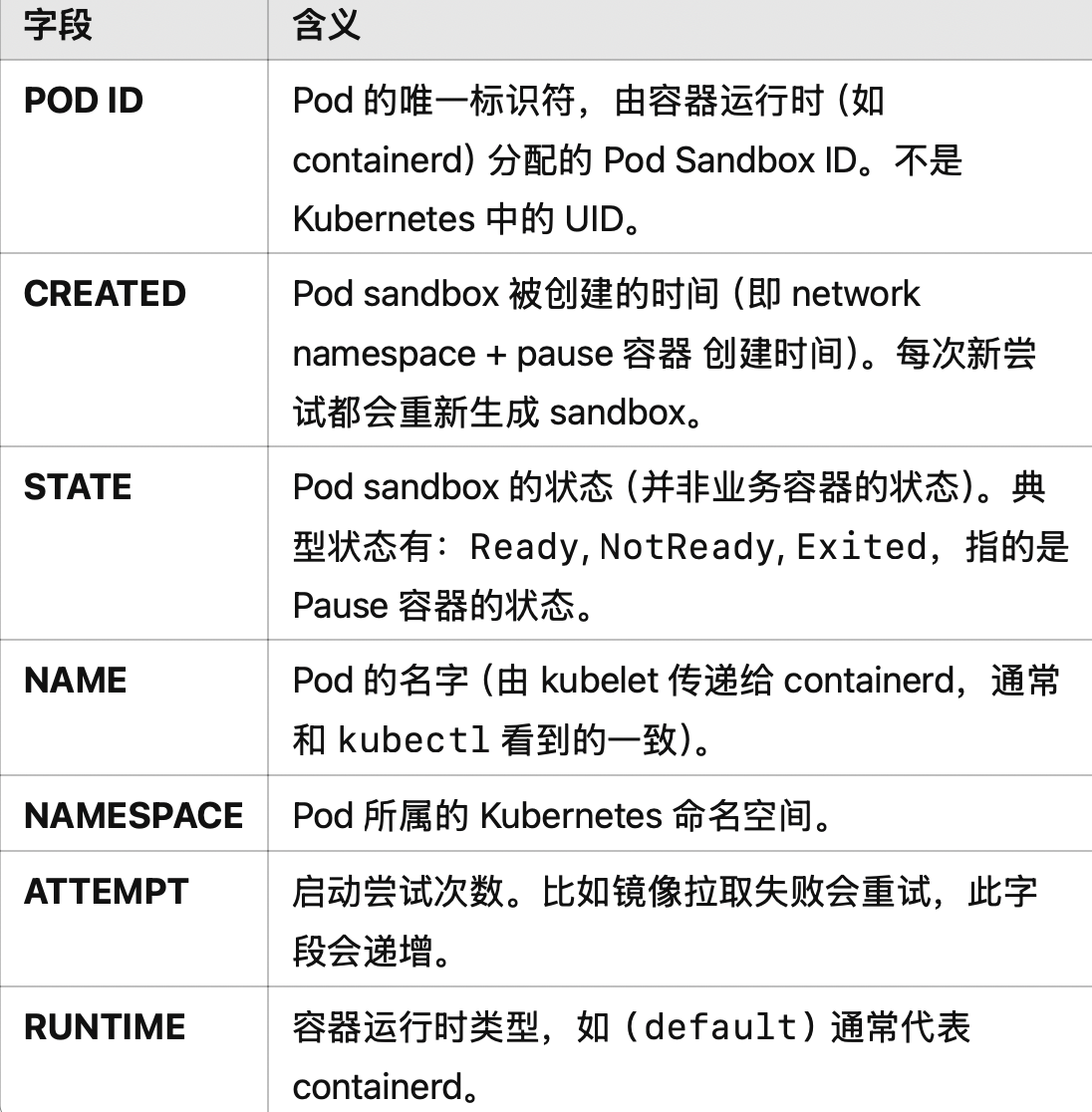
可以注意到,crictl pods中所获得的pods,并不是我们想象中的业务pods,而是Pod sandbox,这一点我们可以根据获取Pod的UID来判断——我们都知道每个Pod都会有自己的UID来进行区分。
kubectl get pod redis-696579c6c8-v2wns -o jsonpath='{.metadata.uid}{"\n"}'
a72e1056-01c3-4f74-80d9-3a7ed79fb3c2
可以发现其UID与当前crictl中的PodID根本不同,也进一步印证了我们的想法。同时,使用crictl inspectp <PODID>可以查到相同的uid,再次印证。
crictl inspectp 8b67484f1bfe4
{
"status": {
"id": "8b67484f1bfe48c4de3cd5b8ee5f343013ae6236491622ee82fb8e865fce0d7f",
"metadata": {
"attempt": 1,
"name": "redis-696579c6c8-v2wns",
"namespace": "default",
"uid": "a72e1056-01c3-4f74-80d9-3a7ed79fb3c2"
},
"state": "SANDBOX_READY",
.....
而其中的state完整结果其实是SANDBOX_READY,又证实了我们之前说的,crictl获得的是Pod sandbox。
所以我会问为什么呢?这一定跟k3s中pod的启动流程有关吧。这里我们简单地描述一下pod的启动流程,后续会根据源码进行剖析。
- kubectl apply -f xx.yaml
- kubenetes API Server
- 调度Scheduled
- kubelet检测到新Pod启动
- kubelet调用容器运行时(containerd)
- containerd创建Pod Sandbox
- 拉取业务容器镜像,启动容器
- kubelet监听容器状态,返回给API Server
而Pod Sandbox是运行时为Pod所创建的一个隔离环境,在这个环境中要有network namespace,一个最小的容器pause容器作为网络占位符,只有这样,Pod内的多个容器才可以共享一个网络空间。
所以回到最初,这两条命令的视角就不同,crictl是从容器运行时出发,关注的是Sandbox的状态;而kubectl是从更高的视角出发,其关注的是业务pods(包括业务容器)的运行状态,是从kubectl那里汇报的最新状态。
检查关键组件容器状态
journalctl -u k3s -f
# 结果
peneuler-riscv64 k3s[2438]: E0409 18:38:08.359021 2438 pod_workers.go:951] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"metrics-server\" with ImagePullBackOff: \"Back-off pulling image \\\"rancher/mirrored-metrics-server:v0.5.2\\\"\"" pod="kube-system/metrics-server-668d979685-jthzj" podUID=e7c219e4-2701-4924-9d7b-84fea6f8274b
4月 09 18:38:08 openeuler-riscv64 k3s[2438]: E0409 18:38:08.359159 2438 pod_workers.go:951] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"helm\" with ImagePullBackOff: \"Back-off pulling image \\\"rancher/klipper-helm:v0.7.3-build20220613\\\"\"" pod="kube-system/helm-install-traefik-crd-ktfth" podUID=3192257c-7e69-4c14-9b4e-d607ce188a88
4月 09 18:38:08 openeuler-riscv64 k3s[2438]: E0409 18:38:08.359193 2438 pod_workers.go:951] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"busybox\" with ImagePullBackOff: \"Back-off pulling image \\\"riscv64/busybox:latest\\\"\"" pod="default/b6" podUID=e423f26e-efd9-44bd-a65b-41dc722f3eb2
4月 09 18:38:09 openeuler-riscv64 k3s[2438]: E0409 18:38:09.604483 2438 resource_quota_controller.go:413] unable to retrieve the complete list of server APIs: metrics.k8s.io/v1beta1: the server is currently unable to handle the request
4月 09 18:38:09 openeuler-riscv64 k3s[2438]: W0409 18:38:09.639045 2438 garbagecollector.go:747] failed to discover some groups: map[metrics.k8s.io/v1beta1:the server is currently unable to handle the request]
4月 09 18:38:11 openeuler-riscv64 k3s[2438]: E0409 18:38:11.357904 2438 pod_workers.go:951] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"local-path-provisioner\" with ImagePullBackOff: \"Back-off pulling image \\\"rancher/local-path-provisioner:v0.0.21\\\"\"" pod="kube-system/local-path-provisioner-7b7dc8d6f5-48jjf" podUID=a4b291fd-db16-498d-a136-9a1432f4649f
4月 09 18:38:14 openeuler-riscv64 k3s[2438]: E0409 18:38:14.357404 2438 pod_workers.go:951] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"coredns\" with ImagePullBackOff: \"Back-off pulling image \\\"rancher/mirrored-coredns-coredns:1.9.1\\\"\"" pod="kube-system/coredns-b96499967-cpbrk" podUID=04219540-713f-44d1-9d2d-7d5acf08222c
......
ps:pod_workers.go来自于k8s的源码
可以发现首先存在的问题是有一些系统镜像在kube-system下的例如helm-install-traefik-crd-ktfth等存在镜像拉取失败问题,在K3sEP02解决RiscV开发板镜像无法拉取问题这篇文章中,我们解决了pause镜像拉取失败问题,当时pause镜像作为最基础的镜像如果拉取失败会导致整个节点无法使用crictl命令拉取镜像。
而这些系统镜像虽然没有直接影响我们k3s的启动,但对于后续的操作产生了较大的影响例如无法暴露服务,Pod间无法进行通信等等问题。
使用以下命令查看pod状态,发现有几个处于镜像拉取失败,并且可以与上面我们使用crictl pods命令的结果对应上。
kubectl get pods -A -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default redis-696579c6c8-v2wns 1/1 Running 1 (148m ago) 32h 10.42.0.35 openeuler-riscv64 <none> <none>
kube-system helm-install-traefik-crd-ktfth 0/1 ImagePullBackOff 0 8d 10.42.0.37 openeuler-riscv64 <none> <none>
kube-system coredns-b96499967-cpbrk 0/1 ImagePullBackOff 0 8d 10.42.0.33 openeuler-riscv64 <none> <none>
kube-system metrics-server-668d979685-jthzj 0/1 ImagePullBackOff 0 8d 10.42.0.36 openeuler-riscv64 <none> <none>
kube-system helm-install-traefik-pv4hv 0/1 ImagePullBackOff 0 8d 10.42.0.39 openeuler-riscv64 <none> <none>
kube-system local-path-provisioner-7b7dc8d6f5-48jjf 0/1 ImagePullBackOff 0 8d 10.42.0.38 openeuler-riscv64 <none> <none>
default b6 0/1 ImagePullBackOff 0 (7d1h ago) 7d21h 10.42.0.34 openeuler-riscv64 <none> <none>
其中CoreDNS是一个很核心的系统组件,如果没有它,我们的Pod间无法进行通信,所以接下来我们先处理CoreDNS镜像的拉取失败问题。
CoreDNS镜像
CoreDNS作为Namespace为kube-system的系统级别镜像,用来实现动态可靠的服务发现.
两个Pod之间进行通信无需硬编码 Pod IP,只需要通过服务名称 service.default.svc.cluster.local 就可以发起请求
这其中 CoreDNS 会与 API Server 交互以获取服务信息——API Server 返回该 Service 的 ClusterIP 和端口。
- PodA 发起 DNS 查询-> CoreDNS ->查询调用 API Server -> API Server 响应 PodB 的 JSON 信息-> CoreDNS 构造 DNS 响应返回给 PodA
与此同时,如果某些 Pod 发生了重启或者迁移,CoreDNS 也会自动更新DNS记录。
接下来我们看看如何将 CoreDNS 镜像移植到我们的开发板上。
首先执行命令确定发现 Coredns 服务并不存在于当前的 k3s 中。
kubectl -n kube-system get svc coredns
Error from server (NotFound): services "coredns" not found
我们默认的 k3s 会去拉取 rancher/mirrored-coredns-coredns:1.9.1 这个镜像,所以我们要自己构建这个镜像在我们的私有仓库中,然后在开发板上拉取这个镜像进行替换使用。
类似于我们当时处理 pause 镜像,不同的是,pause 镜像在 k8s 的源码中是有其源码的,而 coreDNS 本质上是一个外部项目,所以我们需要从其 Github 的源码入手。
1.方法一:本地交叉编译
因为 CoreDNS 是用 Golang 编写的,而 Go 是可以指定架构进行编译的,并且支持 riscv64,所以我的初步思路是将其源码下载到我的mac上并指定为riscv64进行交叉编译。
git clone git@github.com:coredns/coredns.git
git checkout v1.9.1
GOOS=linux GOARCH=riscv64 make
但是这样在构建的过程中会遇到问题
link: golang.org/x/net/internal/socket: invalid reference to syscall.recvmsg
make: *** [coredns] Error 1
GOARCH=riscv64 时,Go 编译器在交叉编译时找不到适用于 RISC-V 架构的某些 syscall 实现,比如 syscall.recvmsg,这是 CoreDNS 或其依赖包 golang.org/x/net/internal/socket 里的系统调用。 这样的问题在网络上也很常见,如这个例子,可以发现 Go 标准库并没有做到实现所有架构的 syscall 支持,特别是一些底层的网络系统调用。
下面给出源码中的 Makefile,可以发现其在构建时会去执行go get,这就是为什么会去找这个系统调用,也是为什么我选择先在mac上进行交叉编译(因为开发板的网络问题)
# Makefile for building CoreDNS
GITCOMMIT?=$(shell git describe --dirty --always)
BINARY:=coredns
SYSTEM:=
CHECKS:=check
BUILDOPTS?=-v
GOPATH?=$(HOME)/go
MAKEPWD:=$(dir $(realpath $(firstword $(MAKEFILE_LIST))))
CGO_ENABLED?=0
GOLANG_VERSION ?= $(shell cat .go-version)
export GOSUMDB = sum.golang.org
export GOTOOLCHAIN = go$(GOLANG_VERSION)
.PHONY: all
all: coredns
.PHONY: coredns
coredns: $(CHECKS)
CGO_ENABLED=$(CGO_ENABLED) $(SYSTEM) go build $(BUILDOPTS) -ldflags="-s -w -X github.com/coredns/coredns/coremain.GitCommit=$(GITCOMMIT)" -o $(BINARY)
.PHONY: check
check: core/plugin/zplugin.go core/dnsserver/zdirectives.go
core/plugin/zplugin.go core/dnsserver/zdirectives.go: plugin.cfg
go generate coredns.go
go get
.PHONY: gen
gen:
go generate coredns.go
go get
.PHONY: pb
pb:
$(MAKE) -C pb
.PHONY: clean
clean:
go clean
rm -f coredns
如何解决呢?可能得去修改 coreDNS 的源码关于系统调用这块了,但是本着不入侵编程的思想(懒比的思想)我们去找其他方法。
2.方法二:找到官方提供的支持riscv的Release
你别说,还真有,只是版本较新,来到了v1.12.1,所以我们暂时先用这个新版本,后续看是否会与开发板上需要的v1.9.1发生冲突。
wget https://github.com/coredns/coredns/releases/download/v1.12.1/coredns_1.12.1_linux_riscv64.tgz
tar -zxvf coredns_1.12.1_linux_riscv64.tgz
构建Docker镜像
FROM alpine:latest
# 换源
RUN sed -i 's#https\?://dl-cdn.alpinelinux.org/alpine#http://mirrors.aliyun.com/alpine#g' /etc/apk/repositories
WORKDIR /root
COPY coredns /coredns
CMD ["/coredns"]
构建镜像并推送至私有仓库,关于私有仓库见移植镜像这篇文章。
docker build --network host --platform=linux/riscv64 -f Dockerfile.coredns -t 192.168.173.76:6000/riscv64/coredns:1.0 .
docker push 192.168.173.76:6000/riscv64/coredns:1.0
然后我们回到开发板上进行拉取并进行类似于pause镜像的适配crictl pull riscv64/coredns:1.0
首先看看当前镜像Pod的描述状态
kubectl get pods -n kube-system -l k8s-app=kube-dns
kubectl describe pod <corednsPodName> -n kube-system
得到的结果如下:
Warning Failed 17m kubelet Failed to pull image "rancher/mirrored-coredns-coredns:1.9.1": rpc error: code = DeadlineExceeded desc = failed to pull and unpack image "docker.io/rancher/mirrored-coredns-coredns:1.9.1": failed to resolve reference "docker.io/rancher/mirrored-coredns-coredns:1.9.1": failed to do request: Head "https://registry-1.docker.io/v2/rancher/mirrored-coredns-coredns/manifests/1.9.1": dial tcp [2a03:2880:f134:83:face:b00c:0:25de]:443: i/o timeout
Warning Failed 15m kubelet Failed to pull image "rancher/mirrored-coredns-coredns:1.9.1": rpc error: code = DeadlineExceeded desc = failed to pull and unpack image "docker.io/rancher/mirrored-coredns-coredns:1.9.1": failed to resolve reference "docker.io/rancher/mirrored-coredns-coredns:1.9.1": failed to do request: Head "https://registry-1.docker.io/v2/rancher/mirrored-coredns-coredns/manifests/1.9.1": dial tcp [2a03:2880:f136:83:face:b00c:0:25de]:443: i/o timeout
Warning Failed 15m (x4 over 19m) kubelet Error: ErrImagePull
Warning Failed 15m (x6 over 18m) kubelet Error: ImagePullBackOff
Normal Pulling 14m (x5 over 19m) kubelet Pulling image "rancher/mirrored-coredns-coredns:1.9.1"
Normal BackOff 4m24s (x47 over 18m) kubelet Back-off pulling image "rancher/mirrored-coredns-coredns:1.9.1"
从k3s的源码 manifests 得知,这些系统级别的镜像(容器)例如traefik,coredns 都在这个目录中以 yaml 文件的形式存在. 这会在 k3s 启动时自动对其进行 Pod 的构建,相当于这是 k3s 自带的 Pod 们。
具体在开发板上的路径是/var/lib/rancher/k3s/server/manifests
现在,我们的思路变成——修改coredns.yaml文件使k3s在构建coredns容器时使用我们私有镜像仓库中的构建的来自于官方v1.12.1中适合riscv64的镜像。 于是我先将其打标签
# 可以用crictl images | grep coredns查看
ctr -n k8s.io images tag <拉取下来的镜像名> docker.io/rancher/mirrored-coredns-coredns:1.9.1
非常值得注意的是,这里打标签前面必须要有docker.io,如果没有的话可能会出现无法识别本地镜像的问题.具体见Github上的相关问题。
之后修改coredns.yaml,将其中镜像名称改为 docker.io/rancher/mirrored-coredns-coredns:1.9.1,拉取策略改为 Never ,并且在arg参数上面添加一行command: ["/coredns"]
最后,删除对应的Pod,k3s会自动重新拉取镜像并构建此Pod,再来检查其运行状态与构建过程。
kubectl delete pod -n kube-system -l k8s-app=kube-dns
kubectl get pods -n kube-system -l k8s-app=kube-dns
kubectl describe pod <corednsPodName> -n kube-system
最终得到结果如下
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 34s default-scheduler Successfully assigned kube-system/coredns-fcc987b6f-nkn92 to openeuler-riscv64
Normal Pulled 33s kubelet Container image "docker.io/rancher/mirrored-coredns-coredns:1.9.1" already present on machine
Normal Created 33s kubelet Created container coredns
Normal Started 33s kubelet Started container coredns
Warning Unhealthy 2s (x18 over 33s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 503
这里虽然出现503错误但是只是健康检测出现问题,可能是配置有误或者插件失败,但是至少容器coredns创建成功了.
并且再次执行journalctl -u k3s -f后可以发现之前的 coredns 创建失败的日志不见了。
解决遗留问题
上面只是解决了CoreDNS组件的镜像拉取问题,但是拉取下来之后其还存在一些其他问题,如果你在上面的构建过程中也遇到了类似问题,请见下方处理方案。
问题1:启动覆盖问题
首先,如果我们下一次重启k3s,就会发现 Coredns 这个容器又构建失败了,并且原因正是我们修改过的 coredns.yaml 文件。
Warning Failed 72s (x2 over 73s) kubelet Error: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: exec: "-conf": executable file not found in $PATH: unknown
这是因为k3s会在重启时自动恢复一些核心组件的yaml文件为默认值,覆盖掉我们的更改。 在K3s官方的Issue中也有类似的问题,而官方文档中的说法也提到了Auto-Deploying Manifests。
所以,根据官方文档中的内容,我们应该先去更改k3s的启动命令,而我们的k3s是由systemd启动的,所以执行sudo systemctl edit k3s,在ExecStart的最后添加上--disable=coredns
For example, to disable traefik from being installed on a new cluster, or to uninstall it and remove the manifest from an existing cluster, you can start K3s with –disable=traefik. Multiple items can be disabled by separating their names with commas, or by repeating the flag.
ExecStart=/usr/local/bin/k3s \
server \
--disable=coredns \
修改 yaml 文件使得 k3s 在启动时使用我们自定义的 yaml 文件。修改内容同上,在 arg 前加一行command["/coredns"]
cp coredns.yaml custom-coredns.yaml
重启服务
sudo systemctl daemon-reexec
sudo systemctl daemon-reload
sudo systemctl restart k3s
至此,可以解决启动覆盖问题,即k3s不会在每次启动时都用默认的coredns.yaml来启动corednsPod,而是使用我们自定义的custom-coredns.yaml文件来进行。
如果后续我们自己从头构建适合 riscv 的k3s可执行文件,直接从源码层面修改镜像名称即可,不用这么麻烦.
问题2:Readiness probe failed
虽然我们使用了本地镜像并且修改了 k3s 默认的关于 coreDNS 的配置,但是仍然会遇到问题. 即上面提到的这个 Readiness probe 的网络问题.
Readiness probe failed: HTTP probe failed with statuscode: 503
对于这个问题,目前我还没有找到合适的解决方法,我个人倾向于是开发板 iptables 的问题,在这里我放一些排查的手段以供后面的操作。
# 查看当前的Corefile内容
kubectl -n kube-system get configmap coredns -o yaml
# 进入Pod调试(但是当前的Pod不断地重启)
kubectl -n kube-system exec -it <coredns-pod-name> -- sh
curl -v localhost:8080/health
# /etc/resolv.conf配置可能出现问题,无法访问到其中的DNS,如果可以进入Pod,检查是否可以访问设置的DNS
wget -O- http://192.168.173.153
# 检查kube-proxy是否生效
kubectl -n kube-system get pods -l k8s-app=kube-proxy
故我们先继续解决其他系统 Pod 以及 Iptables 等问题。
总结
对于 CoreDNS 系统组件,我们发现其官方给出了支持 riscv 的版本,所以无需我们自己重新编译. 我们选择的方法是本地构建对应的镜像并拉取到开发板上,并修改掉源码中的名称为我们构建的名称,最终实现了镜像的替换.
但是这是否太过于依赖于本地的构建?我们应该能做到从某个能够拉取的地址自动拉取,可以将docker.io这个修改为我们自己的服务器吗?
这是我们后续要探索的方向之一.
export INSTALL_K3S_EXEC="--system-default-registry=your.registry.com"
INSTALL_K3S_SKIP_DOWNLOAD=true bash k3s-install.sh
后续更新
最近在 k3s 的官方源码 fork 中找到了一位大佬的 fork,其对于 coredns.yaml 只进行了以下的修改:
image: "%{SYSTEM_DEFAULT_REGISTRY}%rancher/mirrored-coredns-coredns:1.11.3"
image: "%{SYSTEM_DEFAULT_REGISTRY}%coredns/coredns:1.11.3"
系统默认镜像一般是docker.io,所以其只是改了个名字?
后续我们在自行构建的时候,暂时决定将这些系统镜像全部放在自己的私有镜像仓库中, 然后在启动 k3s 的时候指定默认仓库为私有镜像仓库.
这里是LTX,感谢您阅读这篇博客,人生海海,和自己对话,像只蝴蝶纵横四海。