引子
在做力扣的题目时,特别是遇到递归问题,需要传入参数,遇到切片的时候经常遇到需要克隆切片的情况,而遇到普通的int类型的时候却不需要。
显而易见,这是一个值传递还是引用传递的问题,所以今天我来总结一下 Golang 中切片的底层原理,为什么在递归中需要克隆它。
同时,在百度的一面中我也遇到了相关的切片题目,具体如下:
func main() {
original := []int{1, 2, 3}
copied := original[:2]
copied = append(copied, 4)
original = append(original, 5)
copied = append(copied, 6)
original = append(original, 7)
fmt. Printin("original===",original)
fmt.Printin("copied==="copied)
}
在这里你可以按下暂停键,考虑一下此时两个切片的输出会是怎样的。带着你的答案与疑惑,继续看下去吧。
切片
这里先简单区分一下数组与切片。
var res [3]int
var res []int
这里第一个指定长度的是数组,而第二个没有指定的是切片;前者是值类型,后者是引用类型可以使用append操作。
简单一句话,为了摆脱数组固定长度带来的束缚,我们使用更为灵活的切片slice。
切片底层
结构与扩容机制
首先总结一句话:切片 a 本身是一个结构体,a 代表底层数组地址(结构体里的 Data 字段),&a 才是结构体变量 a 本身在内存中的地址。
type slice struct {
array unsafe.Pointer // 指向底层数组的指针
len int // 切片的长度
cap int // 切片的容量
}
其扩容机制如下:
- 当对切片进行 append 操作时,如果切片的长度小于其容量,Go 会直接在原底层数组的空间内添加元素,并更新切片的长度。
- 如果切片的长度等于或超过其容量,Go 会创建一个新的底层数组(通常是原来容量的 2 倍),将原数组的内容复制到新的数组中,并返回新的切片结构体。切片中的指针、长度和容量都会更新为新的数组和容量。
需要注意的是,为什么说切片是引用类型:切片本身是一个结构体(值类型),但它内部的指针指向底层数组。因为它内部包含了指针,所以切片被认为是引用类型。
其在堆栈上的表现如下:栈中保存结构体,堆中保存底层数组。
a := []int{10, 20, 30}
栈区:
+----------------------+ ← &a = 0xc00000e030
| 切片结构体 a |
| Data: 0xc0000140a0 | →→→→ 指向堆上的底层数组
| Len: 3 |
| Cap: 3 |
+----------------------+
堆区:
+----------------------+
| 10 | 20 | 30 | ← a.Data = &a[0] = 0xc0000140a0
+----------------------+
append扩容的注意点
append是给原切片的当前长度的下一个位置添加元素,其扩容机制如上所述,但是需要注意的是
- nil切片在append时会被当作len=0, cap=0的切片处理,所以如果对nil切片进行append其会自动为你分配一个新的底层数组,即指向底层数组的指针会发生改变。
func main() {
var res []int
fmt.Printf("res结构体的地址是 %p, res指向底层数组的地址是 %p", &res, res)
res = append(res, 1)
fmt.Printf("res结构体的地址 %p, res指向底层数组的地址是 %p", &res, res)
}
append每次会生成一个新的结构体值,但是其变量本身在栈上的位置不变,但是指向底层数组的指针如果不扩容就不变。
path = append(path, 1)可以验证&path不会发生改变——放到递归中就是每一层的path都是同一个path,其&path不变(即使底层数组变化&path也不变)- 这意味着每次append之后返回的新的结构体中三个变量:底层数组指针,长度,容量;只有长度是一定在变化的,其他两者要看是否发生了扩容。
- 值得注意的是,在递归回溯类问题中父递归会根据长度来判断当前切片中的值有哪些——即使底层数组不变,但是长度发生了变化。这一点在后面常见问题有所体现。
扩容机制带来的坑(必须len>=cap去扩容)
s1 := []int{1, 2, 3}
s2 := s1[1:2]
s3 := append(s2, 10)
可以思考这段代码三者的结果是什么,看似没有修改s1,其实其值已经被修改了;这也是后面回溯的题目我们为什么要克隆path的原因。
- append(arr, arr …)
这里的省略号代表着什么?回到 append 的最初底层定义func append(slice []Type, elems ...Type)
第二个参数是可变参数,但是类型需要与 slice 切片中元素的类型相同
arr := []int{1, 2, 3}
newArr := append(arr, arr...) // 如果不写...则会报错,因为后面的arr是切片,而前面的Type是int
fmt.Println(newArr) // 输出: [1 2 3 1 2 3]
这样写的含义是使用 … 展开切片 arr, 从而等效于append(arr, 1, 2, 3)。
省略号仅适用于展开切片和表示可变参数。
len与cap
长度和容量作为Golang切片中的核心概念,通过尝试下面这段代码,我们可以略窥一二。
s1 := make([]int, 3, 6)
s2 = s1[1:3]
s1[1] = 1
s2 = append(s2, 2)
如果此时打印s1与s2的内容,会是什么呢?请先思考。
常犯的错误是:第三句执行完之后其底层数组是[0,1,0],然后append时没有发生扩容,所以二者的底层数组是相同的,打印出的二者应该都是[0,0,2],但结果并不是,s1仍是[0,1,0],s2是[1,0,2],所以为什么?
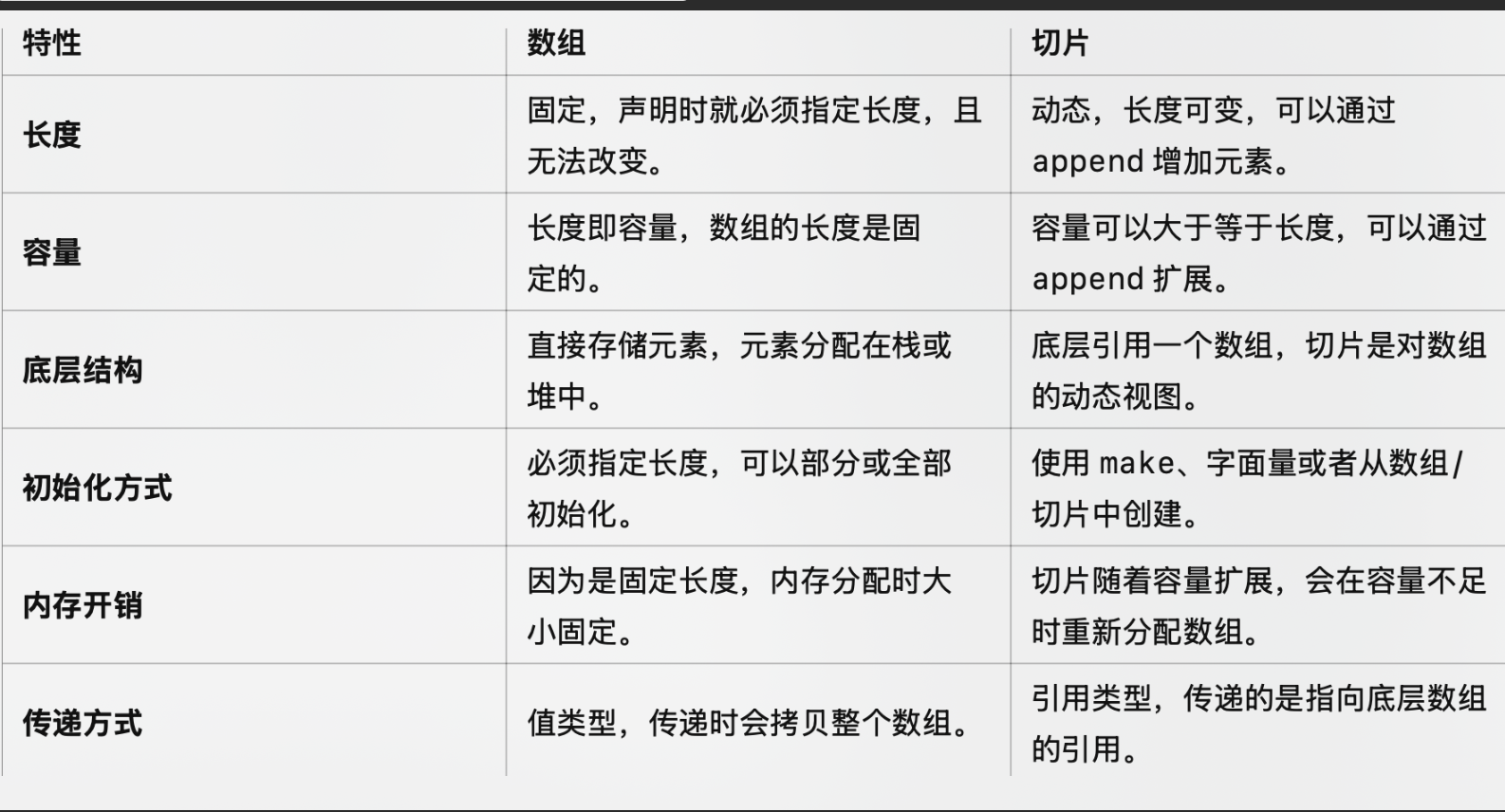
请先记住这个概念:cap(slice) = 原始数组末尾 - slice 的起始位置
起初s1长度为3,容量为6,底层数组前面3个值为0,后面3个未使用;当s2 = s1[1:3]时,s2切片的底层数组指针指向的是第二个位置,这就导致其长度为2,容量为5
在修改s[1] = 1时,底层数组共享,二者都能看到这个修改(如果修改的是s[0]=1呢?可以想想,结果很明显s2看不到,因为其起始位置是第二个位置)
最后append(s2, 2)时,并不会发生扩容,但是s2的长度要+1,二者也都能看到,第四个位置变为2.
具体如图所示:
接下来,如果我们继续向s2中append三个数,3,4,5,后果是什么呢?这里就涉及到append的扩容机制了,我们之前说过。
当3,4添加之后,s2的长度已经来到了5,注意,此时其len=cap了!要发生扩容了!但是对于s1呢?仍然保持着cap=6>len=5,所以不扩容。
最后二者分道扬镳,不再共享底层数组了(指针指向两个不同的地址),s2的容量也会扩大两倍来到10.
切片的初始化
看完上面的长度与容量后,我们借此来讨论一下切片的初始化。
make初始化
对于 make 一般有以下三种不同的初始化,分别是:声明长度为0;声明指定长度;声明指定容量(当然既声明长度又声明容量也是可行的)
a := make([]int, 0)
b := make([]int, n)
c := make([]int, 0, n)
看到b有些亲切,我们平时做题时有时声明path就这样来写的。这三种写法有什么区别呢?
- 显而易见,a的底层数组并没有开辟(长度为0),假如我们每次只append一个值,当我们进行多次append操作时,a会发生多次的扩容,这么多次的扩容会导致什么问题呢——原来旧的底层数组没有人用了,会引起GC的垃圾回收,从而影响性能。(关于GC的事,我们挖个坑后续补充)
- 而bc的底层已经开辟好了空间,有一点不同是,添加元素时需要对b进行
b[i]=x这样的添加,对于c需要进行c = append(c, x)——因为 append 会给切片的末尾去添加元素。 - 带来的区别就是,遇到向切片中添加元素的情况时,b和c基本不会发生扩容,a在不断地扩容,性能大打折扣。
- b和c对比呢?大家可以猜猜更倾向于谁
在性能上,b要优于c一些,仅仅是a little,因为c要不断地去append;但是,考虑到代码的书写方便,我们还是更喜欢c的append,因为b[i] = x这个在某些复杂的情况下得计算,不是简单的顺序。
但是话又说回来,a就一定不好吗?虽然其会发生许多次的扩容,但是如果我们事先并不清楚该设置多少的长度或者容量,反而a在扩容次数较少的情况下会更好。
那么这又是一个CPU和memory的二选一问题了。
但是我们仍然建议你再声明任何切片的时候如果可以预知长度或者容量,就提前声明,即使你要遍历一遍传来的字符串等,因为如果不提前声明,扩容带来的性能损耗远高于遍历等操作。
例如二维动态规划dp数组的声明常见写法
n := len(text1)
m := len(text2)
dp := make([][]int, n+1) // 0~n n+1
for i := range dp {
dp[i] = make([]int, m+1)
}
如果没有后面这段for循环,我们只是创建了 n+1 个 nil 的行,直接访问 dp[0][0] 会直接 panic 数组越界。
字面量初始化
s1 := []int{1, 2, 3, 4, 5}
s2 := []int{}
var s3 []int
- s1 是一种直接给值的初始化,长度=容量
- s2 没有初始化,长度为0,容量为0
- s3 与 s2 的区别是其只声明但未初始化,所以这是一个空切片 nil
从现有数组获得切片
这就是我们常见的“切割”操作,a[1:3],代表着取a[1],a[2]这样一个左闭右开区间。
- 不会创建新的底层数组,而是创建一个新的切片结构体
- 新结构体的指针指向自己指定的起始位置,例如
a[1]
区分nil slice和empty slice
先说结论,nil slice一定是empty slice,但是empty slice不是nil slice.
A nil slice equals nil, whereas an empty slice has a length of zero. A nil slice is empty, but an empty slice isn’t necessarily nil
回到上面的初始化,其实最基础的是不是这几种写法
var s1[]string
s2 := []string(nil)
s3 := []string{}
s4 = make([]string, 0)
- 对于1来说,是空指针,没有底层数组(平时做题自己上来就
var res []int) - 对于2来说,是一个语法糖,本质也是1
- 对于3来说,是空,但有底层数组,但不是nil
- 对于4,与3相同
但是,无论是 empty 还是 nil,对其进行 fmt.Println(s) 打印输出时,都会显示 [],这是 golang 设计的格式化约定。
那么 empty 和 nil 这两个概念有什么区别呢?如果此时对二者进行 JSON 序列化,结果立马就会有所不同。
var s1 []float32 // nil
customer1 := customer{
ID: "foo",
Operations: s1,
}
b, _ := json.Marshal(customer1)
fmt.Println(string(b))
s2 := make([]float32, 0) // empty
customer2 := customer{
ID: "bar",
Operations: s2,
}
b, _ = json.Marshal(customer2)
fmt.Println(string(b))
// 结果如下
{"ID":"foo","Operations":null}
{"ID":"bar","Operations":[]}
值得注意的是,append对两类切片的操作相同。
为什么我们要分这么清呢?上面的JSON序列化已经告诉你了——对前端或接口定义要求严格的系统(比如 [] 是必须字段)就很关键
- 未赋值
nil - 空数组
[]
检查空
由此引申出一个问题,如何判断一个切片为空?是用x == nil吗?很明显不是,对于[]我们无法判断,所以我们应该从长度出发if len(x) == 0,完美地覆盖了两种情况。
copy的坑
开门见山:当你想把某个切片拷贝给另一个切片时,copy函数会选择两个切片中长度的较小值进行逐值拷贝。
所以,如果我们还是像上面那样声明切片的话,很容易发生拷贝失效的问题(长度最小值为0了)
src := []int{0, 1, 2}
var dst []int
copy(dst, src)
fmt.Println(dst)
输出结果为 [], copy 不像 append 那样会进行扩容,所以发生了拷贝失效。
所以还是劝自己写成声明长度或者容量的方式。
做题中的问题
明白了切片的底层原理之后我们再来看看常见的问题,以下面的递归代码举例,本示例代码出自于力扣78子集问题,一道经典的回溯问题。
回溯Clone
func subsets(nums []int) [][]int {
var res [][]int
var path []int
var dfs func(int)
dfs = func(index int) {
if index == len(nums) {
res = append(res, slices.Clone(path))
return
}
// 不选
dfs(index + 1)
// 选
path = append(path, nums[index])
dfs(index + 1)
// 最后进行回溯
path = path[:len(path)-1]
}
dfs(0)
return res
}
需要注意的点在于这句res = append(res, slices.Clone(path)),可以发现每次我们收集结果的时候都进行了克隆——克隆的作用在于创建一个新的切片,复制path当前的内容。
为什么要克隆?如果改成res = append(res, path)会怎么样?
由于 path 切片在代码中作为全局变量,被传入闭包函数中会被全局共享,即每一层递归其实使用的是同一个path结构体,如果不克隆,每次收集的时候都收集到的是当前的path状态。
而后面的递归过程中进行回溯操作,path 值发生变化,导致之前收集到的 res 受到影响。(我们默认不发生扩容)
所以我们需要对其进行克隆,每次都保存一份当前那一刻的path的快照。
何时回溯&为什么回溯
题外话,如果我们不使用闭包函数的写法,上面那段代码会是这样的。
func subsets(nums []int) [][]int {
var res [][]int
dfs(nums, 0, []int{}, &res)
return res
}
func dfs(nums []int, index int, path []int, res *[][]int) {
if index == len(nums) {
clone := slices.Clone(path)
*res = append(*res, clone)
return
}
// 不选当前元素
dfs(nums, index+1, path, res)
// 选当前元素
path = append(path, nums[index])
dfs(nums, index+1, path, res)
// 不需要回溯
}
疑问1:这里为什么要Clone?
- 其实在本题的条件下,不需要Clone——因为这种函数写法是值传递,导致决策树每层递归的path都是独立的,不再是上一段中的全局变量了,我们即使后面在append修改,但修改的不是当前层的path;且收集结果只在根节点收集
那么在力扣上尝试一下是这样的
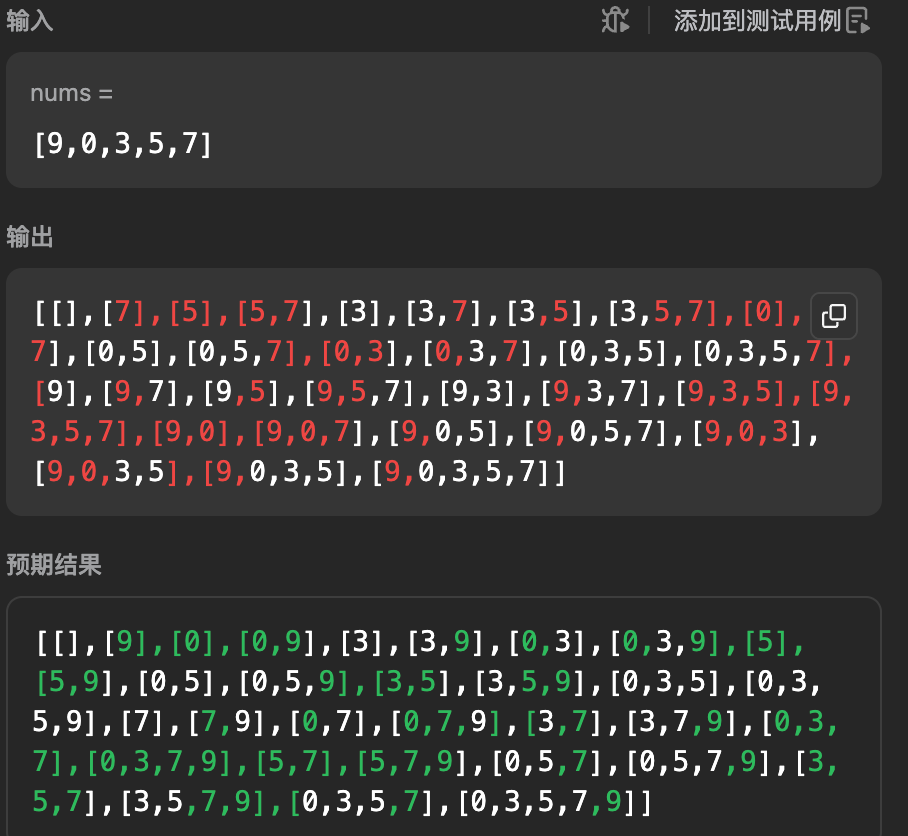
- 其实仔细看两个答案是一样的,只是力扣要求我们必须以他的答案顺序,那么为什么呢?在平时写代码时如果我们在后面修改了前面的元素,例如如果后面修改了
path[0] = 1那么就会影响到我们已经收集好的结果。(默认没有发生扩容,底层数组共享) - 总结:递归中虽然每层的 path 不同,但是仍可能共享着底层数组,发生修改后可能会影响已经收集过的结果,故为了代码的健壮性我们必须Clone
疑问2:既然每层的 path 切片不同,但是其底层数组相同,那为什么不需要回溯?
- 值得注意的是,我们的 path 刚开始是空的,所以一旦发生 append 就一定会发生扩容(这一点在上面的 append 注意点中提到过),而扩容后底层数组就会不一样—nil 切片在 append 时会被当作 len=0, cap=0的切片处理的情况。
- 而不需要回溯的原因在于每次我们都是值传递,即使底层数组共享,但是从子递归回到父递归时,还是父递归那一层的path状态——回到上层递归时,path会从下层的状态恢复到上层的状态,例如从
[2]恢复到[],故自然不需要回溯,这样的写法自动给我们回溯了。
拿一个示例代码举例:
package main
import (
"fmt"
"slices"
)
func main() {
fmt.Println(subsets([]int{1, 2}))
}
func subsets(nums []int) [][]int {
var res [][]int
path := make([]int, 0, 10) // 初始容量为 10,不让他扩容
dfs(nums, 0, path, &res)
return res
}
func dfs(nums []int, index int, path []int, res *[][]int) {
fmt.Printf("path: %p, &path: %p, len: %d, cap: %d\n", path, &path, len(path), cap(path))
if index == len(nums) {
clone := slices.Clone(path)
*res = append(*res, clone)
return
}
// 不选当前元素
dfs(nums, index+1, path, res)
// 选当前元素
fmt.Printf("path: %p, &path: %p, len: %d, cap: %d\n", path, &path, len(path), cap(path))
path = append(path, nums[index])
fmt.Printf("path: %p, &path: %p, len: %d, cap: %d\n", path, &path, len(path), cap(path))
dfs(nums, index+1, path, res)
fmt.Printf("path: %p, &path: %p, len: %d, cap: %d\n", path, &path, len(path), cap(path))
// 不需要回溯
}
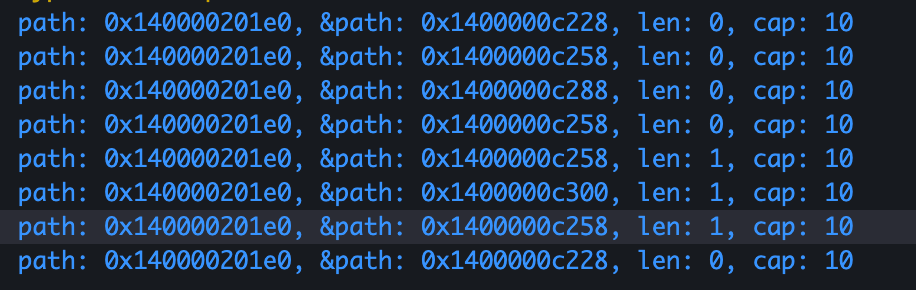
关注第一次进入时的&path和最后一次的,发现二者是一样的,并且path的长度也恢复了,意味着path内的值也恢复了。
这里也留了一个隐藏坑,具体见补充问题中。
疑问3:这里为什么 res *[][]int 呢?
- 因为函数的值传递,每次传入的res如果不加这个
*就会导致每次传的都是一个副本,一个拷贝,即函数里面的res和你外面传过来的res不是一个切片结构体,那么在返回的时候自然无法获得正确结果——需要加上*进行
补充问题:为什么底层数组是一样的,但是path中保存的值却不一样呢?
- 其实这也是一个非常关键的问题,涉及到了Golang对切片的设计哲学——数据共享,但视图独立。
- 因为我们底层数组一样,Golang的切片使用len变量来保证不同层级的视图独立——回到父递归时,由于其len还是0,所以我们的父递归path就只能看得到这个
len=0的切片了,而不再是子递归中的len=1的切片。
对比两种写法可以发现,闭包中使用的path是全局变量,需要回溯,需要克隆;而独立声明函数的写法中的path对于每层(决策树)递归都是一个独立的切片(值传递的缘故)即使底层数组可能发生共享,但是其依靠len变量进行层级之间的分隔,使其做到每层递归都是独立的。
一句话总结:切片是结构体,传参传结构;结构中有指针,共享底层
类比问题
上面两种写法一种使用全局变量+闭包的写法,很明显必须回溯必须Clone;一种采用独立声明函数的方式。如果我再来一种完全闭包函数的写法呢?
func subsets(nums []int) [][]int {
var res [][]int
// var path []int
var dfs func(int, []int)
dfs = func(index int, path []int) {
// 对于每个元素都会选或者不选,这会形成一颗决策二叉树,走到叶子节点收集结果即可。
if index == len(nums) {
res = append(res, slices.Clone(path))
return
}
// 不选
dfs(index + 1, path)
// 选
path = append(path, nums[index])
dfs(index + 1, path)
// 最后进行回溯,其实不需要回溯,原因同上,递归过程中每一层path独立根据len进行分割视图。
// path = path[:len(path)-1]
}
dfs(0, []int{})
return res
}
也不需要回溯,原因同上。
还有一种写法,在append上做出了一个小修改dfs(index+1, append(path, nums[index]))——把两步结合在了一步。
我们把append结果直接传到了dfs参数中,并没有多写path = append(path, nums[index])。有什么不同呢?
- 后者直接传递了一个新的切片结构体进去,子递归发生的修改不会影响父递归的path(这是这种写法的优点,父path还是len=0)
- 前者先append后,父递归的path已经是修改过的了,通过dfs再传入的是修改过的path;
总结递归回溯写法
虽然Golang的切片特性以及值传递的特点可以帮组我们忽略回溯的编写,但是一旦使用全局变量就一定得回溯。
而使用全局变量这一点就类似于Java中的List,所以为了统一起见,我们都显式地将回溯语句写出来。
与Java简单比较
Java中通常使用ArrayList<T>动态数组,可以做到随机访问,其底层也有一个数组,提供了add,remove,get,set等方法。
public class ArrayList<E> {
private Object[] elementData; // 底层数组
private int size; // 当前元素数量
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
}
}
也会发生扩容,使用Arrays.copyOf重新分配新数组。
与切片不同的是,ArrayList是一个类,是一个引用类型,故传入参数是引用传递,不是Go中的值传递,所以对于上面那个*res,Java是不需要的,直接修改的原对象。
List<Integer> arrayList = new ArrayList<>();
arrayList.add(1); // golang中得用append
int val = arrayList.get(0);
补充Slices包的用法
- Clone(slice)强制拷贝所有元素到新的底层数组,不共享内存
- Equal(a, b)
- Compare(a, b)
- Index(slice, val)
- Delete(slice, i, j)删除下标范围[i,j)的元素,将前后两部分进行拼接
- Sort(slice)对支持$<$运算符的进行升序排序,底层调用了
sort.Slice - Max(slice)
总结
切片,本身是个结构体,包含着指向底层数组的指针,长度,容量这三个属性;在函数值传递的过程中,在函数内部操作的是切片的副本,与原来的切片结构体地址不同,但是只要不发生扩容,底层的数组是相同的,但是仍需注意可能指针指向在数组的不同位置导致看到的值并不相同;如果想要相同切片,需要传入其地址;
append操作不影响&path即切片结构体自身的地址,在栈中(因为其长度总会发生变化),与上面相同,只要不发生扩容,底层数组指针就是相同的。
我们强烈建议在预知切片的容量或者长度的情况下,对切片的初始化声明其容量或者长度,将大大地降低扩容带来的性能损耗。
这里是LTX,感谢您阅读这篇博客,人生海海,和自己对话,像只蝴蝶纵横四海。
引用
- 《100 Go Mistakes and How to Avoid Them (Teiva Harsanyi)》
- ChatGPT
- Leetcode