引子
字符串操作在任何语言中的地位都十分重要,在上篇关于 Golang 中特殊的切片讲完之后,这一次我准备进入 Golang 中字符串的底层世界,包括引用总结自<100 Go Mistakes and How to Avoid Them (Teiva Harsanyi)> 书籍的注意事项。
先拿一段力扣上的代码来说吧,本题是125验证回文串,大概要求是这样:如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。字母和数字都属于字母数字字符,s 仅由可打印的 ASCII 字符组成。
func isPalindrome(s string) bool {
var filtered []rune
s = strings.ToLower(s)
for _, c := range s {
if unicode.IsLetter(c) || unicode.IsDigit(c) {
filtered = append(filtered, c)
}
}
// 处理完后判断回文
left, right := 0, len(filtered)-1
for left < right {
if filtered[left] != filtered[right] {
return false
}
left++
right--
}
return true
}
这段代码中有一个在其他语言中没见过的东西 []rune,可以看到,我们先将 s 全部小写化,再遍历判断是字母还是数字最后全部添加回了这个 rune 切片当中(由于不知道长度,所以没有提前声明切片长度),然后使用双指针进行判断回文。
那么我们就来研究一下为什么要多次一举将字符串转换,并且还新开辟了一片空间专门保存,这看起来是有损性能的不是吗?如果换成其他语言例如Java,Python,会怎么处理呢?
本篇文章将梳理 Golang 关于字符串的各种常见知识点,并且在每个知识点后都会与 Java 进行对比学习(以 JDK8 为准)。
string底层
Go:
type stringStruct struct {
str *byte // 指向底层字节数组的指针
len int // 字符串的长度
}
首先要注意的是 string 的不可变性,只读。在 Golang 的底层,字符串是由一个字节数组构成的,就像切片指向底层数组那样。
Java:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[]; // 存储字符
private final int offset; // 起始位置(早期为了 String.substring() 设计的)
private final int count; // 字符串长度(同样是为了 substring)
private int hash; // 缓存hashCode,提高效率
}
底层是一个 char[] 字符数组,这一点与 Golang 不同
说到字节数组,我们就不得不考虑,什么是字节?
Unicode/UTF-8
这当然是一个简单的不能再简单的概念,但是为了引出rune的概念,我们得看看 Golang 是如何利用字节的。在此之前我们需要引出两个基础概念:
- charset字符集
- encoding编码方式
看本节标题就知道Unicode是字符集,UTF-8是编码方式
在讨论字符集时,我们常听到 ASCII,它表示每个字符的 Code Point 的值。 而 Code Point 标志着每个字符在字符集中的编号,即字符的逻辑(抽象)编号。 例如,字符 ‘A’ 的 Code Point 是 U+0041, 对应的 ASCII 是 65。
Go 语言使用的是更通用的 Unicode 字符集,它不仅兼容 ASCII,还能表示更广泛的字符,如中文、表情符号(如 😊)等,因此更加包容和国际化。
关于编码方式,其关心的就是如何将字符集中的 Code Point 转换为二进制的形式供硬件理解使用,UTF-8是Golang在标准库中采取的编码方式,其一般使用1~4字节来编码;例如如果是一个汉字,他会用3字节编码。
用一个例子来总结上面两个概念,‘汉’这个字符的字符集是 Unicode ,其 Code Point 是 U+6C49 ,要将其转换为二进制形式我们需要使用UTF-8编码方式,并需要3个字节进行编码:0xE6, 0xB1, 0x89,最终形成一个二进制。
那么Java呢?
在早期, Unicode 还没有那么多的字符的时候,16位两字节恰好可以表示所有的字符,所以 Java 采用 16bit 来表示 char 类型,一个 Java 字符 = 一个 Unicode 字符。
并且对这些字符的编码采用 UTF-16 的方式,即2字节编码,而不是1~4字节编码,(但是后续例如 emojy 表情的出现,使得 Java 对这些特殊字符采取了4字节编码的方式)
那么 UTF-8 与 UTF-16 的区别就在于8的灵活性1~4字节,和16的死板性全部2字节,当英文字母多的时候8所占的字节就少,但当汉字多的时候16所占变少。所以相对而言, Golang 的编码方式更加适合网络传输,节省空间。
rune类型
rune is an alias for int32 and is equivalent to int32 in all ways. It is used, by convention, to distinguish character values from integer values
在源码中官方注释称 rune 是 int32 类型的别名,相当于 int32 类型,按照惯例用来区分字符值和整数值。
上面提到过,Go 使用至多4字节进行编码,也就是 32bit;而 rune 就是用于表示 Unicode 字符的内建类型,用来存储 Code point 这个编号的,故本质上是一个 int32 类型
用一段代码来演示:
func main() {
s := "hello"
r := []rune(s)
for i, v := range r {
fmt.Printf("r[%d] = %d (char: %c, code point: %U)\n", i, v, v, v)
}
}
// 输出结果如下
r[0] = 104 (char: h, code point: U+0068)
r[1] = 101 (char: e, code point: U+0065)
r[2] = 108 (char: l, code point: U+006C)
r[3] = 108 (char: l, code point: U+006C)
r[4] = 111 (char: o, code point: U+006F)
可以发现 rune 用来表示(or存储)一个 Unicode 字符的 Code Point。
当我们执行 fmt.Println(rune('A')) 的时候,它会输出 65,代表着 ‘A’ 的 Code Point 的值。
当然我们也可以粗略地将 rune 看作字符串中的每一个字符,即 Go 中字符字面量是 rune.
那么Java呢?
Java 中的 code point 是通过 1个char 或2个char组合而成的一个 int 型整数(之所为会有2个上面说过了,为了应付新出现的字符)
String s = "𝄞a"; // U+1D11E
System.out.println(s.length()); // 3,因为 "𝄞" 占 2个char + "a" 1个char
System.out.println(s.codePointCount(0, s.length())); // 2个code point
rune与byte
最早我们提到过,Go 中字符串指向字节数组,那么这里就引出来一个致命问题,为什么 Go 的设计者要引入 rune 这个概念,到底有什么作用呢?
- byte 是 uint8 的别名,仅能表示 0-255 的值,所以我们说的’汉’这个字符不能单个表示,得多字节表示。
- 所以如果只用字节操作多字节字符,就需要手动处理,容易出错。
- rune 是 int32 的别名,其可以直接单独表示某多字节字符。从程序员的角度来看,不需要考虑编码问题,不关心这个多字节字符由几个字节编码。
- rune 有效区分了字符和编码,并为我们屏蔽了下面的细节。
那么 Java 呢?
JDK9也意识到了2字节的编码方式太浪费内存了,毕竟大部分还是以英文字母形式出现的,所以将底层的字符数组改为了字节数组,并且设置不同的编码器按情况编码,不再拘泥于 UTF-16。(但只要 coder 为1,整体都要用 UTF16编码)
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final byte[] value; // 存储字节数组
private final byte coder; // 编码器 0=LATIN1(单字节),1=UTF16(双字节)
private int hash; // 缓存hashCode
}
但是 Java 的向后兼容性很强,平常用的方法还是继续使用就好,作为开发者就好像无事发生,透明的。s.charAt(i)
概念理清楚后,接下来让我们看看可能遇到的坑。
常见问题
这里引用100 Mistakes 中列举出来的问题加以说明巩固。
len(s)
s := "汉"
fmt.Println(len(s))
猜猜这里会输出1还是3?显然,字符串的底层还是字节数组,这是逃不掉的命运,所以len函数输出的是一个字符串的字节数组长度,而不是 rune 的长度。
同样的,在 Java 中 s.length() 返回的不是字符数,而是底层的 char 单元的数量,比如我们上面提到过的音符字符,它会占两个 char 单元,所以整体长度为3而不是2。
range遍历字符串
s := "hêllo"
for i := range s {
fmt.Printf("position %d: %c\n", i, s[i])
}
fmt.Printf("len=%d\n", len(s))
// 输出结果如下
position 0: h
position 1: Ã
position 3: l
position 4: l
position 5: o
len=6
两个问题:
- 下标2怎么不见了?
- 为什么第二个输出了Ã?
很明显,ê 并不是一个ASCII字符,其需要不止一个字节表示;
但这并不能回答我们的问题,核心在于:range s 中的 i 指向每个字符底层字节数组中的起始位置,s[i]自然也就输出的是起始位置处的字符。
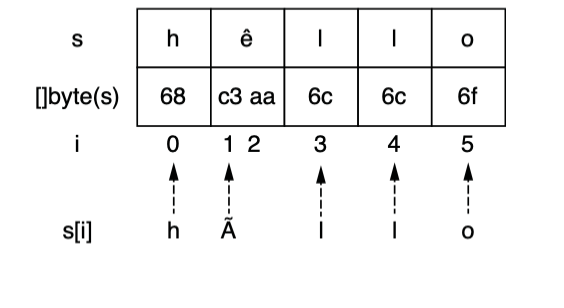
那该如何规避这个问题呢?在range的时候不要用下标,直接使用其值。发现下标还是指向的是底层字节切片的起始下标。
for i, r := range s {
fmt.Printf("position %d: %c\n", i, r)
}
//
position 0: h
position 1: ê
position 3: l
position 4: l
position 5: o
或者更常见的方法,转换为[]rune切片。好处在于下标是对的上的,就表示每个字符在字符串中的位置。
s := "hêllo"
runes := []rune(s)
for i, r := range runes {
fmt.Printf("position %d: %c\n", i, r)
}
//
position 0: h
position 1: ê
position 2: l
position 3: l
position 4: o
这里再补充一下,s[i] 这样的操作会输出第i个字节。
所以在对于普通的英文字符串进行遍历访问时,s[i] 基本等同于字符访问;而对于多字节字符(中文等)这样访问就很容易出 bug。
- 用 range s 遍历字符
- 转换为 rune 切片
[]rune(s),按照下标进行访问
这也就回答了我们最开始的问题,那段回文代码中为什么要使用 rune,就是为了防止多字节字符的影响。
那么 Java 呢?
String s = "Go语言";
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
System.out.println(c);
}
上面我们说到的 char 单元的概念你应该还记得,没错就是那个音符,charAt(i)会按照 char 序号,第几个就是第几个 char。
但是遇到音符我们的 charAt 就不能解决了,因为音符一定是由多个 char 组成的,charAt(i) 时我们会将这个音符“撕裂”,推荐使用提供的 API codePointAt 会识别 code Point 是一个 char 还是两个 char。
String s = "A😊B";
for (int i = 0; i < s.length(); ) {
int cp = s.codePointAt(i);
System.out.println(Integer.toHexString(cp));
i += Character.charCount(cp); // 注意步长是1或2
}
Trim方法
Go 的 strings 包下包含了多种操作字符串的方法,其中容易出问题的是 trim 类的方法。
- ‘TrimRight removes all the trailing runes contained in a given set’ ,而 TrimSuffix 是真正移除给定 set
- TrimLeft 和 TrimPrefix 同理
- Trim 是 TrimRight 和 TrimLeft 结合体
需要补充的是,strings包下有很多好用的方法,如果我们想操作字节数组该怎么办呢?
要把 []byte 转为 string 然后利用 strings 最后再转回去吗?
其实 Go 的 bytes 包也为我们准备许多类似于 stirngs 包中的方法,可以直接操作字节数组。
连接字符串
由于 string 是不可变的,所以我们如果简单地用 ‘+’ 来连接那岂不是不断开辟新的底层字节数组然后将内容复制进去。
他不会像切片那样共享底层数组,因为其不可变性。
对此,Go 标准库提供了一个好方法 strings.Builder
func concat(values []string) string {
sb := strings.Builder{}
for _, value := range values {
_, _ = sb.WriteString(value)
}
return sb.String()
}
这会一次性分配大内存,避免多次复制。其底层实际上还是一个字节切片,每次 WriteString 时就是给这个切片中 append
到这里如果你看过之前关于切片底层的文章,你会敏感地发现向这个字节切片进行 append 不是也从0开始的吗?然后不是还会发生扩容吗?感觉效率仍然不是很高。
所以 Go 还为我们提供了一个附加方法,如果我们可以知道这个 Builder 的总长度,可以预先声明,利用 sb.Grow(x)方法,带来极大的性能提升。
最后,平时开发中(也是我在百度代码中见的最多的)还是使用 fmt.Sprintf(),fmt.Sprintf() 来格式化连接字符串较为常见。
message := fmt.Sprint(500, "internal server error")
那么 Java 呢?
我们平时好像也用+号,例如String s = "Hello" + "World";但实际上 javac会在编译时直接优化成 String s = "HelloWorld";;如果是 a+b,底层会优化为 StringBuilder
所以 Java 官方还是推荐我们使用 StringBuilder(当然 StringBuffer也可以,线程安全)
String concatenation is implemented through the StringBuilder(or StringBuffer) class and its append method
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 100; i++) {
sb.append("data" + i);
}
String result = sb.toString();
和 Golang 有点类似对吧。也可以使用 join String result = String.join(",", listOfStrings);
其实这么看来 JVM 已经为我们自动优化了,而 Golang 则需要我们自己注意一下。
截取字符串
s := "hello world"
sub := s[0:5] // sub == "hello"
如果我们直接用 [:]来截取的话, sub 的底层字节数组并没有改变还是持有着 s 的底层数组,看似没有什么太大的问题,如果这个 s 是一整个很大的 log 呢?
这就会让内存压力很大,很大的 log 并不能及时地得到 GC 处理,因为我们 sub 还在用它。
建议的解决方案有两个
sub = s[0:5] subCopy := strings.Clone(sub)显式复制,会将这部分字节数组复制到一片新的空间中从而避免共享。sub := string([]byte(s[0:5]))先转换为[]byte,再转换回string——Go 会 重新分配新的只读内存,拷贝 byte 数组内容,得到另外一个独立的字符串,不再共享。
Java 中使用 substring String sub = s.substring(0, 5);并且在 JDK8 以后它不会带来上面的问题,他会直接创建一个新的字符串和它的 char 数组(JDK7 以前会)
比较字符串
在 Golang 中,两个字符串可以直接用运算符号进行比较,其底层执行的是字典序的比较。
- 相等性比较
- 逐个比较字节,只有长度相同,对应位置字节全部相同时,才相等。
- 其他比较(
<,>,<=)- 直接字典序比较,不论长度;对应位置谁的字典序小谁就小。
替换字符串中的字符
在力扣 1410HTML 实体解析器题目中,我们可以直接使用 Golang 的 NewReplacer() + Replace() 方法进行多个位置上的一次性替换。
func entityParser(s string) (ans string) { return strings.NewReplacer(`"`, `"`, `'`, `'`, `>`, `>`, `<`, `<`, `⁄`, `/`, `&`, `&`).Replace(s)}
原理大概如下:
NewReplacer()形成了一棵决策树,这会建立起一个高效的搜索引擎。Replace()会执行一次性扫描,将符合决策树中的内容进行替换。- 这样的时间复杂度只有一趟,是 $O(n)$的,而如果我们对每个字符都使用
ReplaceAll()的话,时间复杂度就是 $O(n*m)$了。
总结
Go 中的 string 我们要注意 rune 和 byte 的区别;注意 len 返回的是什么;注意如何遍历,连接,截取字符串。
Java中就三类 String, StringBuilder, StringBuffer;由 char[] 转向 byte[],但还是 char[] 更常用, JDK8 的功劳。
这里是LTX,感谢您阅读这篇博客,人生海海,和自己对话,像只蝴蝶纵横四海。
引用
- 《100 Go Mistakes and How to Avoid Them (Teiva Harsanyi)》
- ChatGPT
- Leetcode