引子
之前的两篇文章关于context和channel,我们都从源码的角度去讨论了其各自的底层原理以及使用方法。
但是我并没有从宏观的角度上来阐述为什么我们需要并发?为什么要设计这两种结构来处理并发,本着做到"what-how-why"的态度,我们今天来深入讨论一下 Go 中的并发。
区分并行和并发
这个已经被说烂的话题为什么我还要拿出来说呢?(因为书里写了,bushi)因为自己对其的理解还不够深刻。英文中并行通常是 Parallelism,并发是 Concurrency.
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
从这句名言可以看出,并发是一种组织结构上的概念,而并行是一种执行上的概念。(这个思想很重要)
同时我们抛出一个问题:同样的程序,并发就一定并行要快吗?
在回答这个问题之前,我们应该先了解 Go 中关于并发和并行的常见概念,也就是 goroutine 与 GMP 调度模型。
goroutine
在我们学的操作系统课程中,通常用线程thread 描述并发,进程描述并行;但是作为 Go 程序员,我们通常用 goroutine 描述并发,thread描述操作系统线程。
- goroutine 可以被视作应用级别的 threads,所以这是一种来自于用户态的调度
- 相当于又把 thread 往里“剥”了一层
那为什么要搞一个 goroutine 出来呢?
- thread 直接由 OS 管理,占用空间大,系统调用和线程调度过程中上下文切换资源消耗大,并且受到 CPU 资源限制,同步问题处理复杂
- goroutine 由 Go runtime 管理,占用空间极小(2KB);运行时的调度器可以将N个 goroutine 映射到 M 个 thread 上,消耗小;Go 提供 context,channel机制处理同步问题容易
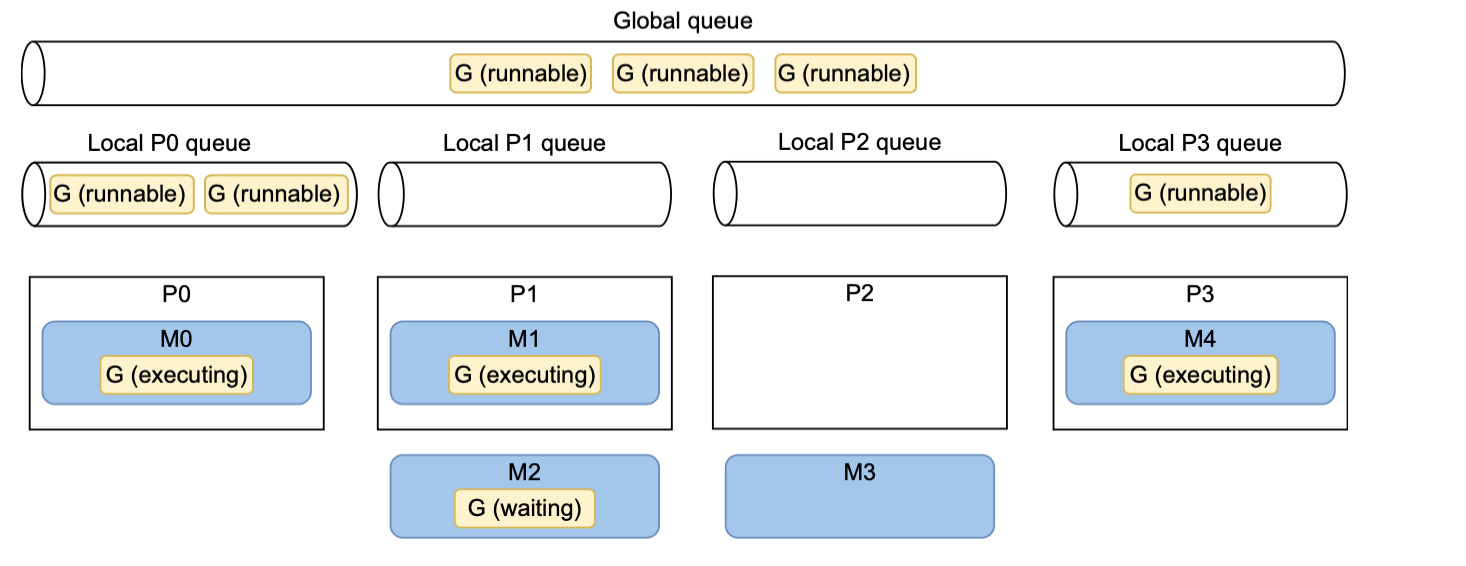
GMP模型
上面提到了调度器的作用,其实就是 Go 的调度模型 GMP(这里简单提及,后续会出文章深究)
- G-Goroutine
- M-OS thread
- P-CPU core
形象的理解就是 M 作为服务员,通过 P 来服务许多的顾客 G,而管理员就是 Goruntime.
每个 goroutine 都有三个状态(类似于 thread 的几个状态,但比其简单)
- Executing
- Runnable
- Waiting
还有一个重要概念,这里简单提一嘴:GOMAXPROCS——代表着默认M的数量,同时也是最多有多少 goroutine 同时处于 Executing 状态。
GOMAX-PROCS is by default equal to the number of available CPU cores;GOMAX-PROCS can be changed and can be less than the number of CPU cores
最后再简单说说 GoRuntime 是怎么调度以保证并发效率的。
采用队列保存 goroutine,有本地队列也有全局队列。 遇到自身没有 goroutine 的时候会进行 work stealing,从其他的队列偷一半过来保证并发效率。
并发一定快吗?
好了,补充了这么多了,希望大家没有忘记上面提出的问题,并发的写法一定比顺序的快吗?
以书中的例子——归并排序举例。 因为归并排序每次将元素分为长度相同的两半,直到无法分,然后又对分出的这些内容进行排序,最后组合在一起(形成了一个树形结构)
如果我们用 goroutine,大概是这样的。
func MergesortV1(s []int) {
if len(s) <= 1 {
return
}
middle := len(s) / 2
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
MergesortV1(s[:middle])
}()
go func() {
defer wg.Done()
MergesortV1(s[middle:])
}()
wg.Wait()
merge(s, middle)
}
结果发现,并发反而要比顺序要慢,这是为什么呢?
- 还记得我们一开始就说过,并发是一种组织结构,是需要调度的,调度是需要开销的。
- 尽管我们已经用了 goroutine 这样一个开销较小的结构,但是对于归并排序,每次把元素划分地太小了,导致每一个任务的开销甚至不如调度的开销,所以并发更加耗时。
如何解决这个问题?很明显是 workload 的缘故,所以我们可以设置一个 workload 的 threshhold,不够这个门槛的顺序执行,超过的并发执行。
并发引起的数据竞争
在上面我们引入了 goroutine 并讨论了 golang 中的并发与并行。接下来讨论常见的数据竞争问题。
首先要明确一点:goroutine 虽然已经创建,但不一定立刻调度运行(Go 的调度器不保证立即运行)也就是我们写的代码的顺序并不是真正的执行顺序。
众所周知,数据竞争一直是并发问题下绕不开的话题。Go 中使用 goroutine 这种更小的结构更应该讨论如何面对数据竞争。
同时 Go 也为我们提供了一个运行时参数-race来检查我们的代码中是否有数据竞争问题。
那我们就来看看 Go 是如何避免数据竞争的。 Go的标准库 sync 下就有一些准备好的方法。
atomic
从单词意思就可以看出来,原子化——不能被打断的操作。atomic.AddInt64(&i, 1)
需要注意的是,其只能作用于具体类型,不能用于像 slices,maps,structs这样的结构。(并且还得指明bit位数)
mutex
这就类似于操作系统课程中的锁,mutex可以主动给数据区上锁打造临界区,这样自然可以处理数据冲突问题。mutex.Lock()
但是可能会发生死锁问题——死锁发生的根本原因是所有 goroutine 都被阻塞,没有任何一个能推进程序的执行。 特别是 main 中的被阻塞,而其他的 goroutine还没来得及启动时,那一定会都堵在那里。
channel
同时,我们也可以用 channel处理数据竞争,关于其底层原理,见我的文章.
这里我们使用的是无缓冲的 channel,因为无缓冲型有一个特点是其必须存在一对接收方与发送方,如果少了其中之一,这个通道就会阻塞。 所以无缓冲的通道具有很强的同步一致性。
有缓冲也可以,但是需要我们进行额外设计。
区分mutex与channel
区分mutex与channel,二者最本质的区别是前者强调上锁形成一个临界区,而后者强调不同 goroutine 之间的通信协作。
mu.Lock(),mu.Unlock()保护共享的内存ch <-1, <-ch发送给通道,通道接收
在 Golang 中有一个原则是:不要通过共享内存来通信,而应该通过通信来共享内存
区分data race和race condition
解决了数据竞争程序就可以一定按照我们想要的顺序执行吗?不一定。例如
i := 0
mutex := sync.Mutex{}
go func() {
mutex.Lock()
defer mutex.Unlock()
i = 1
}()
go func() {
mutex.Lock()
defer mutex.Unlock()
i = 2
}()
很明显,没有数据竞争问题,但是最终结果会是1还是2?得看两个协程的运行先后顺序了。
A data race occurs when multiple goroutines simultaneously access the same memory location and at least one of them is writing. An application can be free of data races but still have behavior that depends on uncontrolled events (such as goroutine execution, how fast a message is published to a channel, or how long a call to a data-base lasts); this is a race condition.
可见 mutex 无法解决执行顺序问题,但是 channel 可以,它的核心思想一直是通过通信来共享数据,而不是通过共享数据来通信。 所以我们可以通过channel解决,第二个操作需要等待第一个操作完成(对其阻塞)
i := 0
done1 := make(chan struct{}) // 用于通知第一个 goroutine 已完成
done2 := make(chan struct{}) // 用于通知第二个 goroutine 已完成
go func() {
i = 1
close(done1) // 通知第一个操作已完成
}()
go func() {
<-done1 // 等待第一个操作完成
i = 2
close(done2) // 通知第二个操作已完成
}()
<-done2 // 等待所有操作完成
fmt.Println(i) // 保证输出 2
具体原理简单解释一下:如果 done1 通道阻塞了,第二个 goroutine会被挂起并加入到接收等待队列,调度器会将其移出可运行队列,并切换其他协程,直到被唤醒。
Go内存模型
上面的执行顺序问题其实在 Go 的内存模型中就已经定义过了。称为多 goroutine 并发操作时的执行顺序规则。 关键在于 happens-before 关系。规定哪些操作必须发生在另一些操作之前。
1.channel 的发送操作在接收完成之前 1.底层用锁和等待队列实现。 2.close 先于所有“因关闭而返回”的接收操作 1.这样就不会出现关闭后仍能接收的情况 3.无缓冲的 channel 接收操作先于发送完成(这一点有些难理解) 1.就是我们说的接收和发送是一对操作,如果没有准备好的发送,接收就会阻塞
goroutine泄漏问题
Context在并发中也是十分重要的一环,用于控制生命周期,具体见这篇文章.最后我们来说一下一个常见问题: goroutine的泄漏——某些 goroutine 在预期之外长期运行或阻塞,无法被回收,导致内存和 CPU 资源浪费,甚至程序崩溃(其实阻塞有时就是死锁)。
- 无缓冲 channel 阻塞:我们之前一直强调 channel 要是成对出现的,如果永久阻塞就会泄漏
- 未关闭 channel 导致接收者阻塞
- 无限循环的:增加退出条件,例如
ctx.Done() - 未处理的 select 分支:最终原因也是堵塞
为了解决堵塞,我们推荐使用有缓冲的 channel,确保关闭通道,使用 context 来控制生命周期,使用 select(case)+default分支结构。
区分 I/O密集型和CPU密集型任务
I/O 密集型任务:网络请求,文件操作,数据库访问。 CPU 密集型任务:数学计算,图像处理等。
由于 Go 的调度依赖运行时,之前我们提到他是在用户态的调度,所以上下文的切换成本比 thread 要低得多。于是可以创建数十万级别的 goroutine. 如果有10000个HTTP请求,他就可以开10000个 goroutine,而由于调度器的存在(GMP模型)实际上只需要少量的 OS thread。 其通信模型 channel 也十分适合这类型的任务。
但是到了 CPU 密集型任务,就得靠 GOMAXPROCS 这个参数了,它是实打实的表征着正在运行的 thread数量,Gol 对于这类任务并没有体现出更优的性能,C/C++ 也许更为合适。
总结
Go 依靠其独特的 goroutine、channel、context结构,展现出优异的并发能力(特别是在I/O密集型任务上) Go 的核心理念是:不要通过共享内存来通信,而是通过通信来共享内存
这里是LTX,感谢您阅读这篇博客,人生海海,和自己对话,像只蝴蝶纵横四海。