引子
上一篇文章中留下了两个问题没有解决
- map 如何扩容
- 为什么原生的 map 线程不安全
其实这两个问题是有联系的,所以这篇文章来解决这两个问题。
map 的扩容机制
本节还是需要用到上一篇文章中的底层 hmap 结构
type hmap struct {
count int // map 中存储的元素个数
B uint8 // 当前 bucket 的数量为 2^B 个
buckets unsafe.Pointer // 指向 bucket 数组
oldbuckets unsafe.Pointer // 指向旧的 buckets(在扩容时使用)
...
}
为什么扩容
- 装载因子超限(主要条件)
- 像 Java 中的 ArrayList 等结构,都有一个装载因子来限制结构的长度,当超过某个限制时就会发生扩容,Go 也不例外。
- Go 硬编码(默认)的装载因子是 6.5;当
map.count / (2^B) > 6.5时,就会发生翻倍扩容。 - 举个例子,之前我们说一个 bucket默认存 8 个键值对,那么如果 map 此时已经存放了 14个键值对了,即
14/2 > 6.5,那么两个 bucket 就不够了,为了减少哈希冲突,需要进行扩容。
- 溢出桶过多(次要条件)
上一篇提到的*overflows指针,就是指向溢出桶,这里先讲讲什么是溢出桶。
之前提到过一个 bucket 容量默认为 8,那么当这个 bucket满了,而下一个 key又要进入这个 bucket 时该怎么办?
- 创建一个新的 bmap(buckect)
- 将原来的 bucket 的
overflows指针指向新的溢出桶 - 最终形成了一个单向链表
这虽然可以在严重的哈希冲突下保证正确的数据读取,但是将 map 的性能降低了,最坏情况下退化到链表查询,复杂度接近 N
好了,那么话说回来,溢出桶过多为什么导致扩容?
因为此时 Go 会认为哈希冲突非常严重,对性能产生了很大的影响,需要重新整理数据,让 key 重新分布,减少溢出桶的使用。具体的扩容规则如下:
- 当B 小于 15 时,溢出桶数量超过了 $2^B$,触发扩容
- 当B 大于 15 时,数量超过 $2^15$时,触发扩容
如何扩容
扩容的核心是数据迁移,将旧的数据迁移到新的 bucket 中,并且这个过程是渐进式的,不是一蹴而就的。
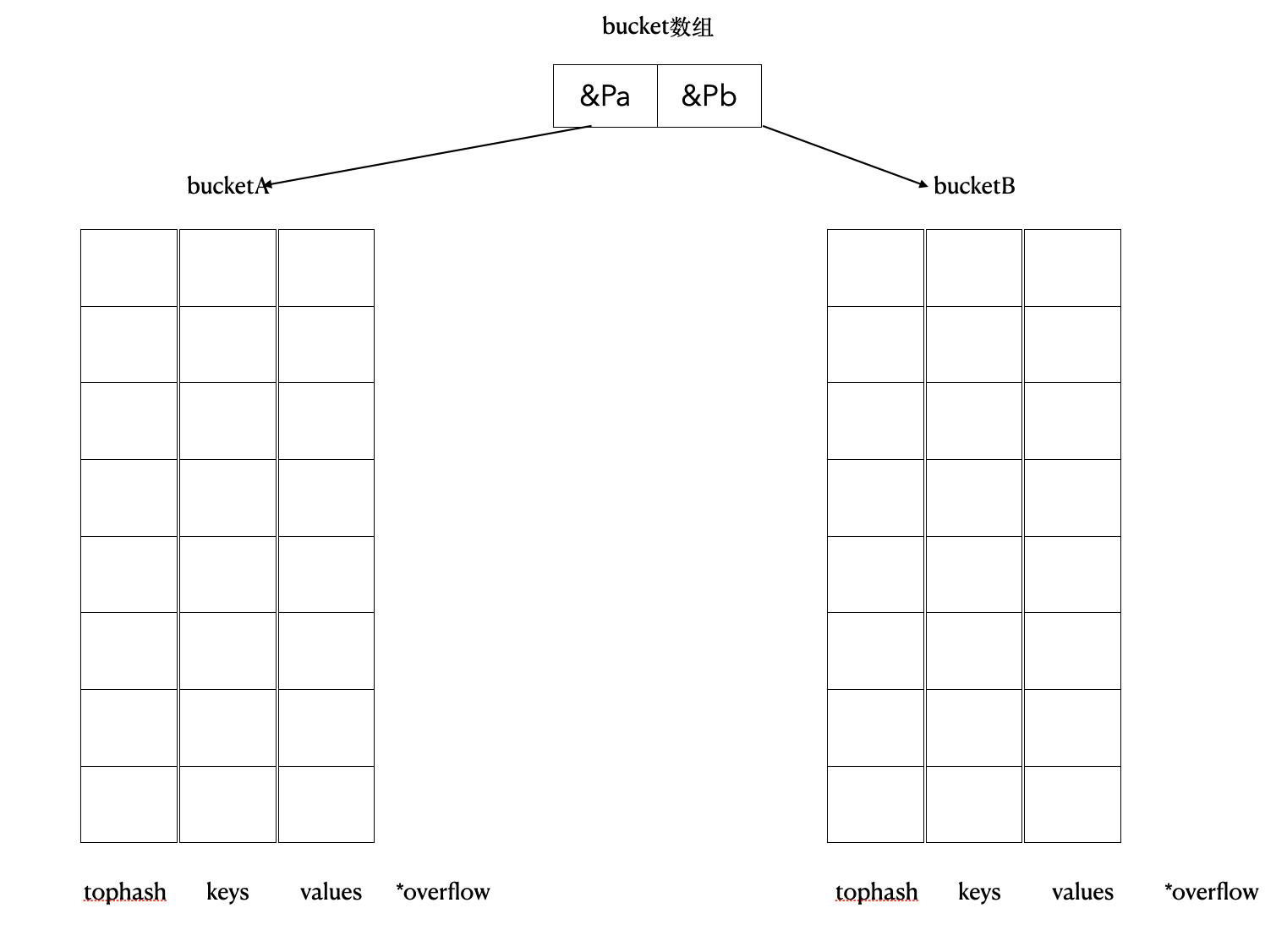
- 翻倍扩容
- 创建新的bucket
- B++
- 分配一个两倍于旧 bucket 数组大小的新 bucket 数组。例如图中长度为 2 的数组变为 4,底层就会有 4 个 bucket
- hmap 结构中指向 buckets 的指针也要发生变化
- 渐进式迁移
- 真正的迁移发生在后续的 map 写入或删除操作中
- 每当读写一次map,就会顺便迁移 1~2 个旧的 bucket 中的数据到新的 bucket 中
- 新位置需要 rehash
- 读操作每次都会去新的 bucket 中查找,找不到再去旧的。这样可以保证每次读到的都是正确的。
- 迁移完成后,最终
oldbuckets指向 nil
- 创建新的bucket
- 等量扩容
- 创建等量的新桶
- B 不变,map 会分配一个和旧 bucket 数组同样大小的新 bucket 数组
- 渐进式迁移
- 创建新的哈希种子
- 将之前高度冲突的 key 重新散列 rehash
- 创建等量的新桶
扩容带来的问题
The number of bucktes in a map cannot shrink
扩容不是一劳永逸的,想象这样一个场景:
你用 map 存储最近一个小时的用户数据,促销开始时百万级用户量的涌入,map 会疯狂扩容;当促销结束后用户逐渐离线,map 中删除了数据但是 map 底层的结构不会被删除,其在堆上的内存不会被回收。
为什么?Go 的运行时认为,一个曾经达到过如此规模的 map,未来很可能再次需要这么大的容量,因此保留这部分内存以避免未来再次扩容的开销。
那么如何解决这种潮汐的流量模式带来的问题呢?我们需要主动打破 map 的生命周期,让 GC 可以回收它。
- 定时重建
- 启动 goroutine,使用定时器周期性地用新的小的 map 来替换旧的 map
- 旧 map 没有引用后就可以被 GC 回收了
- 分片/分时 map
- 不要使用一个大 map 来存储数据,而用一个 map 切片来存,每个 map 负责存储一个时间段内的数据
- 根据数据时间戳来写入,定时清理
- 这样数据洪峰只会撑大其中几个分钟的 map,当洪峰过去后,这些 map 会被自动回收。
线程安全问题
最后,我们来回答本系列最开始的问题,为什么原生的 map 线程不安全。
原生 map在设计之处就是为了追求性能,而忽略了并发环境的使用。如果在并发环境下使用会发生什么呢?
原生 map
以我们上面的扩容过程举例,如果一个 goroutine触发了扩容,而另一个 goroutine正在读 map,那么可能会读到:
- 旧 bucket 数据
- 新 bucket 数据
- 读操作访问内存被释放,触发 panic
当然,并发写导致的数据竞争就更显而易见了。
总结一下就是 map 的操作有很多小步骤,并不是原子性的,任何一个步骤都可能被其他 goroutine 打断插入。
如何处理并发问题
最常见的两种方式是:加锁 or 分片处理降低锁的粒度。
- 分片
- 将一个大的 Map 再进行哈希,分成一个个小的 map,不同的 key 会落在不同的小 map 中,从而减少大 Map 下的竞争
- 对小 Map 同样需要使用
sync.RWutex锁进行控制 - 会增加锁的内存开销,但是竞争压力大大减少
- 经典的
concurrent-map,适用于常规读写混合场景。
来自于 GPT 的举例:
type shard[V any] struct {
mu sync.RWMutex
m map[string]V
}
// ShardedMap: string 键的分片 map
type ShardedMap[V any] struct {
shards []shard[V]
seed maphash.Seed
}
sync.Map
这个包中的 map 结构可以通过读写分离来避免并发冲突,适用于读多写少的场景。
具体结构如下所示:
type Map struct {
mu Mutex
// 无锁,用于缓存,读取时先从read读;如果未命中再去dirty读
// 原子操作read
read atomic.Pointer[readonly]
// 带锁,写入时,键值对首先存在dirty中;所有新增,删除,修改操作
dirty map[any]*entry
// 缓存未命中次数,当达到阈值,read缓存会被替换成dirty中的最新数据
misses int
}
// 存储可无锁访问的键值对
type readOnly struct {
m map[any]*entry
amended bool // true if the dirty map contains some key not in m.
}
仔细看就像是 os 中的缓存系统。
- 读操作
- 首先从只读的
read map中查找,原子读取。 - 如果没有找到,加锁然后去
dirty map中查找;找到后解锁,misses计数器+1
- 首先从只读的
- 写操作
- 先尝试更新
read map,但是 key 必须存在于read map中 - 如果不满足,加锁去
dirty map写入;解锁
- 先尝试更新
- 数据同步
- 当
misses计数器达到一定的阈值时,说明read map命中率过低 - 此时会进行一次升级(数据同步),将
dirty map的内容提升为新的read map
- 当
与操作系统中的缓存操作有异曲同工之妙啊。
总结
那么关于 map 的有关知识就到这里结束了,上下两篇,从底层结构到初始化再到扩容最后到并发安全问题。
这里是LTX,感谢您阅读这篇博客,人生海海,和自己对话,像只蝴蝶纵横四海。